Illumination Invariant Face
Recognition
Wei Wu
1.
Introduction
Face recognition plays a more and more important role in the world nowadays, with application in security system, credit card verification, etc. In the past two decades, various algorithms have been proposed, such as principle component analysis (PCA) [1], linear discriminant analysis (LDA) [3], independent component analysis (ICA) [4], support vector machine (SVM) [5], neural networks [6], and so on. These algorithms are all proved to be effective in certain conditions, but have a worse performance in some other situations. In general, there is no algorithm that is robust enough to work perfectly in every possible environment that people may have.
One of the most challenging problems is how to deal with the variable illumination on human face. As stated by Adini et al, ��The variations between the images of the same face due to illumination and viewing directions are almost always larger than image variations due to change in face identity��[7]. However, most face images obtained from daily lives are affected by the illumination more or less. Therefore, a well-developed face recognition system has to handle it properly, so that the system is eligible for practical use.
In my project, I try to implement one possible way to do the illumination invariant face recognition proposed by Liu et el [2]. The project has two main parts, namely, face recognition by PCA and face image restoration. In order to show the performance of the face restoration, I use the Eigenface technique [1] to do face recognition on the Yale database [8] before, and after face restoration. Experimental results are given in the report and we will find the recognition rate is largely increased.
In Section 2, the detail of eigenface technique is provided. Then I discuss about the algorithm to restore a face image to frontal light in Section 3. In Section 4, I focus on what job I did for the project. Experimental results are given in Section 5 and a brief conclusion is drawn in Section 6.
2.
Principle component analysis and eigenfaces
Eigenface was proposed by Turk and Pentland [1] back in 1991. This is one of the most popular techniques in face recognition, and many algorithms later were based on or motivated by it.
Assume we have a set of N face images, denoted as Ii, where i = 1, 2, ��, N. Then, PCA is applied to derive a set of eigenvectors describing the eigenspace where the face images lie. Let I be the mean image of these face images and �� the corresponding covariance matrix. Then we have
![]() (1)
(1)
where T means the transpose of a vector. The eigenvalues problem is then solves as follows:
![]() (2)
(2)
where �� is a diagonal matrix whose diagonal elements are the eigenvalues of �� with their magnitude in descending order, and �� is a matrix whose ith column is the ith eigenvector of ��. In order to obtain the eigenspace, we choose K eigenvectors corresponding to the K largest eigenvalues, which capture over a large portion of the variations of the images.
Let ��s be the matrix consisting of the K eigenvectors, and In be a new face image. The projection of In onto the eigenspace is represented as follows:
![]() (3)
(3)
where ��
is a K![]() 1 vector containing the K projection coefficients.
1 vector containing the K projection coefficients.
However, the computation of the eigenvalues and eigenvectors of the
matrix �� is not an easy job for
typical image sizes. If the number of data points (N) in the image spaces is less than the dimension of the space, there
will be only N-1 meaningful
eigenvectors. Therefore, we can solve for the eigenvectors of �� by first solving for the eigenvectors
of an N by N matrix. Let A = [A1, A2, ��,
AN], where Ai = Ii �C I. We construct the N by N
matrix L = ATA, and find
the N eigenvectors, vi of L. These vectors can
then be used to determine the N-1 eigenvectors
of ��.
![]() (4)
(4)
where ��i is the ith eigenvalue of L.
In particular, a set of images (15 persons with 11 images each) are
first read into a large matrix. Since we need vectors, a 80 by 80 matrix is
reshaped in to a 6400![]() 1 vector. Then, the mean vector of these images are computed,
and subtracted from every image. After that, we can derive the 15 by 15 matrix L (because we have 15 persons in the
database), and its eigenvectors. Finally, the 14 eigenvectors of �� is calculated, and forming the
transformation matrix ��.
1 vector. Then, the mean vector of these images are computed,
and subtracted from every image. After that, we can derive the 15 by 15 matrix L (because we have 15 persons in the
database), and its eigenvectors. Finally, the 14 eigenvectors of �� is calculated, and forming the
transformation matrix ��.
The training part of eigenface method is quite simple. For every person, we have one or several face images. These images are projected to the eigenspace, and each has a vector of projection coefficients. In this project, because we only use one image for training, the projection vector is the only information about the person.
For every new face image, we subtract the mean face from it, and project it into the eigenspace. Since every person only has one image, hence one point in eigenspace, the nearest neighbor rule is then used to classify the face image. I tried two methods for similarity measure, i.e., angular (cosine) and Euclidean distance, which are defined respectively as:
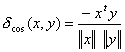 (5)
(5)
![]() (6)
(6)
And the
experiments show the Euclidean distance is much better in this project.
The source code for face recognition in
Matlab is provided in Appendix 1.
3. Image restoration by iterative processing
In this part, I restore an image under
random lighting condition to the one under frontal illumination. The method
described here does not require the estimation of lighting direction or face
surface, which makes it very fast. The algorithm is based on the mean face of
the training set, so sometimes it will also introduce some errors.
3.1 Initial image restoration
The whole algorithm is under one
assumption, that the two faces under the same lighting condition will be
similar to each other after enough blurring. In particular, if we adopt
Gaussian low-pass as the filter, then the blurred image is given by:
![]() (7)
(7)
![]() (8)
(8)
where F is the Gaussian filter, Iik represents a face image of the ith person captured under the skth light direction, Ir0 denotes a face image of another person captured under the frontal light, �� is the albedo of the surface, ni the unit inward normal vector to the surface, and s a column vector signifying the product of the light source intensity with the unit vector for the light source direction.
If the size of the filter is large enough, with the assumption we have:
![]() (9)
(9)
This means two faces under the same lighting will be very similar to each other after blurring. Therefore, we have
![]() (10)
(10)
Consequently, by using equation (7)�C(10), the face image under frontal illumination for the ith person can be estimated from the image captured under an arbitrary lighting direction by:
![]() (11)
(11)
In other words, for a face image under random light source, the face under frontal illumination can be estimated by the ratio between the blurred image of itself and the blurred reference image. One important feature of this method is the image is restored pixel-wisely. For every pixel, we multiply it by the ratio between the pixels of the same location in the two blurred image. In fact, it does not sound good theoretically; however the results are satisfactory. An example of initial restored image is illustrated in Fig. 1(b).
The initial reference image used is the mean image of all the training samples. Then I use an iterative process and update the reference image every iteration.


(a) (b)
Fig. 1. The raw image and the initial restored image.
3.2 Face
image processing
Shading is caused by the illumination. In order to restore the face image into frontal illumination, it is helpful to do the segmentation and edge extraction first.
First, I segment a reconstructed image to obtain the broad region of the eyes, eyebrows, nose and mouth using an optimal threshold segmentation method [9]. Then I apply morphological erosion and dilation to it to remove some noise points, and merge some uncovered regions. The first segmented image is denoted as R1. An example is shown in Fig. 2 (a). Second, I segment the raw image to obtain the dark region, using the same method. Erosion and dilation are also applied, and we can get R2, as in Fig. 2 (b).


(a) (b)
Fig. 2. The segmentation of reconstructed image and raw image.
The Canny operator [10] is used to extract the edges from the initial reconstructed image. The edges we are interested in are these caused by shading. Therefore, we can update the edge image by selecting pixels that only lie in the dark region of R2, but not in R1. An example of this updated image is illustrated in Fig. y.

(a) (b)
Fig. 3. The edge image of the reconstructed image and its update.
Based on the edges caused by shading, we can then improve the blurring performance by adopting an adaptive filtering method, i.e., a larger size is used at pixel positions far away from the edges, and a smaller size close to the edges. This method can reduce the effect of edges largely. In the project, the filter size at a particular pixel position is set at 3 if there is at least one pixel in its 3 by 3 neighborhood; and set at 5 if there is at least one pixel in its 5 by 5 neighborhood, but not in 3 by 3 range. If no edge point is found in its 5 by 5 neighborhood, the filter size is set at 7.


(a) (b)
Fig. 4. The Gaussian filtered raw image and reference image.
3.3
Iterative processing
Since the quality of an initial restored face image is not yet satisfactory, an iterative processing algorithm is then adopted to approach a truer appearance. In every iteration, the previous restored image is used as the new reference image, to reconstruct a better face image under frontal illumination. The detail is stated as follows:
(1) In the tth iteration, the reference image is the mean image (t=1), or the previous reconstructed image (t>1). Apply segmentation to the reference image and the raw image.
(2) Apply edge extraction to the reference image, and update it according to the segmented image above.
(3) The reference image and the raw image are then blurred by using an adaptive Gaussian filter based on the edge image.
(4) A new restored face image is recalculated by using Eq. x..
(5) The mean square difference d between the new restored image and the previous image is calculated. If d is less than the threshold dmin, or the iterative number t>tmax, the iteration will be stopped; otherwise, return to (1).
In the experiments, I have tried a bunch of combinations of dmin and tmax. In the end, I choose dmin = 3, and tmax = 5, which gives the best results. In Fig. 5, images after different iterations are given. The visual difference between each other is very slight. However, experiments show that the recognition rate will be higher when the number of iterations performed is 3 or 4 (depending on the image itself).




Raw image t=1 t=2 t=3 t=4
Fig. 5. The restored images after t iterations.
4. My
work
My work includes mainly three parts: programming the face recognition part in Matlab; programming the face restoration part in Microsoft Visual C++; and testing the performance of the whole system.
4.1
Programming in Matlab
Matlab is widely used for research purpose. In this project, I use Matlab for face recognition because of Matlab��s convenient matrix operation. A face image is represented by a point in a high dimension space. In order to obtain its vector, we need to project it into the eigenspace. Moreover, we need to compute the eigenvectors and eigenvalues of a matrix to get the transformation matrix. All of these manipulations are very easy to conduct in Matlab, and thus I can focus more on the algorithm itself.
4.2
Programming in Microsoft Visual C++
The reason to use C++ is its efficiency. For programs requiring a lot of loops, C is almost always much faster than Matlab. In this project, the face restoration part involves a lot of operations at every single pixel, where even more loops are done. The disadvantage of C is it is harder to read and write images to different file formats.
In order to focus more on the image analysis part, I include Intel Image Processing Library (IPLib) v2.5 [11], and Intel Open Source Computer Vision Library (OpenCV) v4.0 [12]. These two libraries are very popular image processing libraries, which can perform a huge amount of image processing functions. However, I only use them for image reading and writing. Because I need more flexibility in the image processing operations in this project, I still programmed functions such as adaptive Gaussian filter by myself. Some functions were modified from previous homework, such as Canny edge detector.
4.3
Testing
Because of the limited time, I can only test my programs in a relatively small database. Yale database [8] has some images with different lighting conditions, and its size is still acceptable, so I use it for the testing.
In the testing, I concentrate on how much the image restoration program can improve the performance of face recognition. After all, the restoration is recognition oriented. Therefore, even the restored images are not visually satisfactory (although I think they are), as long as they can achieve a high recognition rate, the restoration program is thought to be effective.
Meanwhile, I also adjusted some parameters during the testing. Still, the criterion is recognition rate. Since the parameters are non-linear, it takes me rather long time to set all these numbers.
5.
Experimental results
In my experiments, the position of the two eyes of each face image was located manually. Each image is normalized to 80 x 80. An elliptical mask is also applied to obtain a ��pure�� face that contains only the interior part of the face image.
The performance of my project is evaluated using the Yale database [8]. The Yale database consists of 15 persons, each person having 11 images, as stated in Table 1.
|
No. |
Condition |
|
1 |
Center light |
|
2 |
With glasses |
|
3 |
Happy |
|
4 |
Left light |
|
5 |
No glasses |
|
6 |
|
|
7 |
Right light |
|
8 |
Sad |
|
9 |
Sleepy |
|
10 |
Surprised |
|
11 |
Wink |
Table 1. The different conditions in the Yale database.
The first image of every person (center light) is used for training, and the rest 10 images are used to test the algorithm. However, from the name of these images, we can find that image no. 2, 3, 8, 9, 10, and 11 focus on the expression variation, which is not the goal of this project. Therefore, I designed 2 groups to test the performance.
|
Group No. |
Images selected |
|
1 |
2,3,4,5,6,7,8,9,10,11 |
|
2 |
4,7 |
Table 2. My grouping method.
Group 1 includes all the images. Group 2 focus on the two images with illumination from left or right direction. From the experiments, I found that the recognition performance for non-Group-2 images does not change obviously, which is because my project only deals with changing in lighting directions.
Some examples of the images in Group 2 are shown in Fig. 6. Before running the program, I use these raw images to do face recognition first, and the recognition rates for Group 1 and Group 2 are 52.0% and 26.7% respectively. The result suggests the eigenface method cannot deal with the changing illumination correctly.
Then, I apply my program to all the images, to restore the images under frontal illumination. The results for examples in Fig. x are illustrated in Fig. 7. From these images, it is easy to find that the shading caused by uneven lighting decreases remarkably, although there are some noise points in the restored images.





Fig. 6. Some example images of random lighting directions from the Yale database.





Fig. 7. Some example images of restored images under frontal illumination.
These images are used to do face recognition again. Since the original training images have been modified too, we also take their restored images as new training images. The recognition rates for Group 1 and Group 2 now are 63.3% and 93.3%, as stated in Table 3.
|
Data set |
Group 1 (All images) |
Group 2 (Lighting from L/R) |
|
Raw image |
52.0% |
26.7% |
|
Restored image |
63.3% |
93.3% |
Table 3. Recognition rates based on the Yale database.
Obviously, this algorithm can significantly improve the recognition rates for face images under random lighting directions.
6.
Conclusion
In my project, I implement a novel method proposed by Liu et el to restore a frontal illumination face image from an image captured under arbitrary lighting conditions. Meanwhile, I also implement the eigenface method to do face recognition and test the face restoration algorithm.
Experimental results show that the method is effective when using the popular Yale database. Moreover, this method has some advantages over many existing methods:
l Only one training image is needed for each person.
l No face surface normal vectors or the lighting direction estimation is required.
l The time needed to restore an image is very short.
However, there are also some drawbacks of this method:
l Face detection (or eye location) has to be highly accurate.
l This algorithm cannot deal with changing poses and expressions.
In the future, one way to make this method more practical is to design a face detector which can scale human face into the mean face automatically. This method requires accurate matching between raw image and reference image. Therefore, for real-time application, sometimes it is not so easy to locate the human eyes with both high accuracy and efficiency.
Another problem is there are a lot of parameters in this method, such as parameters in Canny operator, eigenface method, iteration processing. To achieve a satisfactory performance, I have to adjust these parameters manually. Nevertheless, these parameters may vary under different situations. Currently, there is no automated way to determine all of these parameters. Thus, another improvement will be how to increase the robustness of the program.
Last but not the least, human eyes are able to distinguish different people not only from their fontal views, but also profiles. Nowadays, most algorithms still focus on the frontal views only. But sometimes profiles are the only available information we can get, e.g., security camera. Hence, in order to play a more active role in our daily lives, face recognition techniques should also include efficient ways to deal with look from all kinds of angles.
clear
dim=15;
eignumber=14;
%
TRAINING %
for (i=1:dim) % Read all the training images
numStr = int2str(i*11-10);
imgName = strcat('e:\test\recface\',numStr,'.bmp');
aa = imread(imgName);
a(i,:,:) = aa;
end
for (j = 1:dim)
for (i = 1:80)
b(j,((i-1)*80+1):(i*80))=a(j,i,:); % Convert matrices into vectors
end
end
d(dim,6400)=0;
d(:,:)=b(:,:);
for (i=1:6400)
meanface(1,i) = sum(d(:,i));
end
meanface = round(meanface / dim); % Calculate the mean face
for(i=1:dim)
d(i,:) = d(i,:) - meanface(1,:); % Subtract the mean face from all
end
g=d*transpose(d);
[eVector eValue]=eig(g); % Compute the eigenvectors
eigValue = eig(g); % and eigenvalues
for (i=1:eignumber)
W(:,i)=transpose(d)*eVector(:,eignumber+1-i)/sqrt(eigValue(eignumber+1-i));
end
% Compute the transformation matrix
for (i=1:dim)
trainingface(i,:) = transpose(W) * transpose(d(i,:));
end % Obtain the transformation coeffcients
%
RECOGNITION %
for (personI=1:15)
for (faceI=1:11)
numStr = int2str((personI-1)*11+faceI);
imgName = strcat('e:\test\recface\',numStr,'.bmp');
recface = imread(imgName); % Read new images
recfacevector(1,6400) = 0;
for (i = 1:80)
recfacevector(((i-1)*80+1):(i*80))=recface(i,:);
end % Also convert to vectors
recfacevector2 = recfacevector - meanface; % Subtract the mean face
pca = transpose(W) * transpose(recfacevector2); % Project to the eigenspace
mindistance = 10000;
for (i=1:dim) % For every person
if ( norm(transpose(pca) - trainingface(i,:)) < mindistance )
found = i;
mindistance = norm(transpose(pca) - trainingface(i,:));
end % Compute the Euclidean distance
end
recMatrix2(personI,faceI)=found; % The new image is classified as
end % the person with least
end % Euclidean distance
% RECOGNITION RATE CALCULATION %
correctNum = 0;
for (personI=1:15)
for (faceI=2:11)
if (recMatrix2(personI,faceI)==personI)
correctNum = correctNum+1;
end
end
end
correctNum / 150 % Recognition rate for Group 1
correctNum = 0;
for (personI=1:15)
faceI=4;
if (recMatrix2(personI,faceI)==personI)
correctNum = correctNum+1;
end
faceI=7;
if (recMatrix2(personI,faceI)==personI)
correctNum = correctNum+1;
end
end
correctNum / 30 % Recognition rate for Group 2
% THE END %
Appendix II. Face restoration program in C++
Because I programmed on Microsoft Visual C++, there are lots of codes for MFC framework
that were auto-generated. Therefore, I only copy the related functions here.
/* FUNCTION TO CALCULATE THE MEAN FACE */
void CFACEDlg::OnMeanFace()
{
CString strFileTitle;
CFileFind finder;
unsigned char value;
IplImage *img, *meanFace;
int mean[80][80],i,j,count=0;
BOOL bWorking =finder.FindFile("e:\\test\\all\\*.bmp");
meanFace = cvLoadImage("e:\\test\\meanface.bmp", 0);
for (i=0; i<=79; i++)
for (j=0; j<=79; j++)
mean[i][j] = 0; // Initiate the sum.
while (bWorking)
{
count ++;
bWorking=finder.FindNextFile(); // Find every bmp file in the directory
strFileTitle = finder.GetFilePath();
img = cvLoadImage(strFileTitle, 0); // Load the image by OpenCV
for (i=0; i<=79; i++)
{
for (j=0; j<=79; j++)
{
iplGetPixel(img, i, j, &value);
mean[i][j] += value; // Compute the sum
}
}
}
for (i=0; i<=79; i++)
{
for (j=0; j<=79; j++)
{
value = mean[i][j]/count;
iplPutPixel(meanFace, i, j, &value); // Write the mean value to the mean image
}
}
}
/* FUNCTION TO SCALE AND MASK THE FACE IMAGES */
void CFACEDlg::OnResize()
{
CString strFileTitle;
CFileFind finder;
unsigned char value;
IplImage *img, *newimg;
int d;
BOOL bWorking =finder.FindFile("e:\\test\\newbase\\*.bmp");
newimg = cvLoadImage("e:\\test\\meanface.bmp", 0);
while (bWorking)
{
bWorking=finder.FindNextFile();
strFileTitle = finder.GetFilePath();
img = cvLoadImage(strFileTitle, 0);
for (int i=10; i<=89; i++)
{
for (int j=10; j<=89; j++)
{
if ( i > 50 ) // Elliptical masking
{
d = (int) (sqrt(1600-((double)i-50)*((double)i-50)/1.7)+0.5);
if ( j > (50 + d) || j < (50 - d) )
value = 0;
else
iplGetPixel(img, j, i, &value);
}
else
{
iplGetPixel(img, j, i, &value);
}
iplPutPixel(newimg, j-10, i-10, &value);
}
}
cvSaveImage(strFileTitle, newimg);
}
}
/* FUNCTION TO BATCH PROCESSING RAW IMAGES */
void CFACEDlg::OnBatch()
{
/* INITIALIZATION */
IplImage * referenceImg = cvLoadImage("e:\\test\\meanface.bmp",0);
IplImage * randomlightImg;
int nrows, ncols, value, i, j, d, count=0, allIter=0;
float iterDif;
CString strIter;
ncols = referenceImg->width;
nrows = referenceImg->height;
unsigned char **refImg, **rdmImg, **iniRefImg, **gauRefImg, **gauRdmImg, **difImg, **oldRefImg, **edge1, **edge2, **seg1, **seg2;
refImg = (unsigned char **)matrix(nrows+32, ncols+32, -16, -16, sizeof(char));
rdmImg = (unsigned char **)matrix(nrows+32, ncols+32, -16, -16, sizeof(char));
iniRefImg = (unsigned char **)matrix(nrows+32, ncols+32, -16, -16, sizeof(char));
gauRefImg = (unsigned char **)matrix(nrows, ncols, 0, 0, sizeof(char));
gauRdmImg = (unsigned char **)matrix(nrows, ncols, 0, 0, sizeof(char));
oldRefImg = (unsigned char **)matrix(nrows, ncols, 0, 0, sizeof(char));
difImg = (unsigned char **)matrix(nrows, ncols, 0, 0, sizeof(char));
seg1 = (unsigned char **)matrix(nrows+2, ncols+2, -1, -1, sizeof(char));
seg2 = (unsigned char **)matrix(nrows+2, ncols+2, -1, -1, sizeof(char));
edge1 = (unsigned char **)matrix(nrows+2, ncols+2, -1, -1, sizeof(char));
edge2 = (unsigned char **)matrix(nrows+2, ncols+2, -1, -1, sizeof(char));
CString strFileName;
CFileFind finder;
BOOL bWorking =finder.FindFile("e:\\test\\test\\*.bmp");
while (bWorking) // For every bmp file in the directory
{
count ++;
bWorking=finder.FindNextFile();
strFileName = finder.GetFilePath();
randomlightImg = cvLoadImage(strFileName,0);
for (i=0; i<ncols; i++)
{
for (j=0; j<nrows; j++)
{
iplGetPixel(referenceImg, j, i, &value);
refImg[i][j] = (unsigned char) value;
if ( i > 40 )
{
d = (int) (sqrt(1600-((double)i-40)*((double)i-40)/1.7)+0.5);
if ( j > (40 + d) || j < (40 - d) )
value = 0;
else
iplGetPixel(randomlightImg, j, i, &value);
}
else
{
iplGetPixel(randomlightImg, j, i, &value);
}
rdmImg[i][j] = (unsigned char) value;
}
} //
reflect(rdmImg, nrows, ncols, 16);
reflect(refImg, nrows, ncols, 16);
gauRdmImg = gaussianFilter(rdmImg, 5, nrows, ncols); // 1st time, use non-adaptive
gauRefImg = gaussianFilter(refImg, 5, nrows, ncols); // Gaussian filter.
/* INITIAL RESTORATION */
for (i=0; i<ncols; i++)
{
for (j=0; j<nrows; j++)
{
iniRefImg[i][j] = (unsigned char) min(255, ( (float)rdmImg[i][j] * (float)gauRefImg[i][j] / (float)gauRdmImg[i][j] ) );
}
} // According to Eq. (11)
/* SEGMENTATION */
seg1 = segmentation(iniRefImg, nrows, ncols, 0); // Segmentation first
seg1 = morph(seg1, nrows, ncols, 0); // Erosion
seg1 = morph(seg1, nrows, ncols, 1);
seg1 = morph(seg1, nrows, ncols, 1); // Dilation three times to get a
seg1 = morph(seg1, nrows, ncols, 1); // better image
seg2 = segmentation(rdmImg, nrows, ncols, 0);
seg2 = morph(seg2, nrows, ncols, 0);
seg2 = morph(seg2, nrows, ncols, 1);
/* EDGE DETECTION */
edge1 = canny(iniRefImg, nrows, ncols);
/* UPDATE EDGE MAP ACCORDING TO SEGMENTATION */
for (i=0; i<ncols; i++)
{
for (j=0; j<nrows; j++)
{
if (edge1[i][j] == 255 && (seg2[i][j] == 255 || seg1[i][j] != 255) )
edge1[i][j] = 0;
}
}
/* ADAPTIVE FILTERING */
gauRefImg = adaGaussian(refImg, edge1, 7, nrows, ncols); // Adaptive Gaussian filter here
gauRdmImg = adaGaussian(rdmImg, edge1, 7, nrows, ncols);
/* RESTORE IMAGE */
for (i=0; i<ncols; i++)
{
for (j=0; j<nrows; j++)
{
refImg[i][j] = (unsigned char) min(255, ( (float)rdmImg[i][j] * (float)gauRefImg[i][j] / (float)gauRdmImg[i][j] ) );
}
}
/////////////////////////////////////////
/* ITERATION BEGINS */
/////////////////////////////////////////
oldRefImg = iniRefImg; // Update reference image
for (int iteration = 1; iteration <=5; iteration ++) // Max number of iteration is 5
{
/* SEGMENTATION */
seg1 = segmentation(refImg, nrows, ncols, 0);
seg1 = morph(seg1, nrows, ncols, 0);
seg1 = morph(seg1, nrows, ncols, 1);
seg1 = morph(seg1, nrows, ncols, 1);
seg1 = morph(seg1, nrows, ncols, 1);
seg2 = segmentation(rdmImg, nrows, ncols, 0);
seg2 = morph(seg2, nrows, ncols, 0);
seg2 = morph(seg2, nrows, ncols, 1);
/* EDGE DETECTION */
edge2 = canny(refImg, nrows, ncols);
for (i=0; i<ncols; i++)
{
for (j=0; j<nrows; j++)
{
if (edge2[i][j] == 255 && (seg2[i][j] == 255 || seg1[i][j] != 255) )
edge2[i][j] = 0;
}
}
/* ADAPTIVE FILTERING */
gauRefImg = adaGaussian(refImg, edge2, 7, nrows, ncols);
gauRdmImg = adaGaussian(rdmImg, edge2, 7, nrows, ncols);
/* RESTORATION */
for (i=0; i<ncols; i++)
{
for (j=0; j<nrows; j++)
{
refImg[i][j] = (unsigned char) min(255, ( (float)rdmImg[i][j] * (float)gauRefImg[i][j] / (float)gauRdmImg[i][j] ) );
}
}
for (i=0; i<ncols; i++) // Compute the difference to the previous image
for (j=0; j<nrows; j++)
difImg[i][j] = abs(oldRefImg[i][j] - refImg[i][j]);
float thd = normImage(difImg, nrows, ncols); // Root square of the sum of the square of
if (watch1 < 3 ) // each pixel��s intensity
break; // If the root mean difference less than threshold,
// then stop the iteration.
for (i=0; i<ncols; i++)
for (j=0; j<nrows; j++)
oldRefImg[i][j] = refImg[i][j]; // Duplicate the new restored image for later use
}
allIter += iteration;
saveImage(refImg, ncols, nrows, strFileName.GetBuffer(16));
} // After processing one image, write it back
float fIter = (float)allIter/count;
strIter.Format("%f",fIter);
AfxMessageBox(strIter); // Calculate the mean number of iteration
}
/* ADAPTIVE GAUSSIAN FILTER */
unsigned char ** adaGaussian(unsigned char **img, unsigned char **edge, int max, int nrows, int ncols)
{
int row, col, flag;
float value;
unsigned char **ret;
ret = (unsigned char **)matrix(nrows, ncols, 0, 0, sizeof(char));
reflect(img, nrows, ncols, 4);
float gKernal3[9] = {(float)0.011660, (float)0.086157, (float)0.011660,
(float)0.086157, (float)0.636620, (float)0.086157,
(float)0.011660, (float)0.086157, (float)0.011660};
float gKernal5[25] = {(float)0.002915, (float)0.013064, (float)0.021539, (float)0.013064, (float)0.002915,
(float)0.013064, (float)0.058550, (float)0.096532, (float)0.058550, (float)0.013064,
(float)0.021539, (float)0.096532, (float)0.159155, (float)0.096532, (float)0.021539,
(float)0.013064, (float)0.058550, (float)0.096532, (float)0.058550, (float)0.013064,
(float)0.002915, (float)0.013064, (float)0.021539, (float)0.013064, (float)0.002915 };
float gKernal7[49] = {(float)0.001296, (float)0.003936, (float)0.007665, (float)0.009573, (float)0.007665, (float)0.003936, (float)0.001296,
(float)0.003936, (float)0.011955, (float)0.023286, (float)0.029080, (float)0.023286, (float)0.011955, (float)0.003936,
(float)0.007665, (float)0.023286, (float)0.045354, (float)0.056641, (float)0.045354, (float)0.023286, (float)0.007665,
(float)0.009573, (float)0.029080, (float)0.056641, (float)0.070736, (float)0.056641, (float)0.029080, (float)0.009573,
(float)0.007665, (float)0.023286, (float)0.045354, (float)0.056641, (float)0.045354, (float)0.023286, (float)0.007665,
(float)0.003936, (float)0.011955, (float)0.023286, (float)0.029080, (float)0.023286, (float)0.011955, (float)0.003936,
(float)0.001296, (float)0.003936, (float)0.007665, (float)0.009573, (float)0.007665, (float)0.003936, (float)0.001296};
// In order to save time, the kernel is pre-calculated.
for(int i=0; i<nrows; i++)
{
for(int j=0; j<ncols; j++)
{
flag = 0;
//3X3 Window
for (row=-1; row<=1; row++)
{
for (col=-1; col<=1; col++)
{
if (edge[i+row][j+col] == 255)
{
flag = 1;
break;
}
}
if (flag == 1)
break;
}
if (flag == 1)
{
value = 0;
for (int row=-1; row<=1; row++)
{
for (int col=-1; col<=1; col++)
{
value += (img[i+row][j+col] * gKernal3[(row+1)*3 + col + 1]);
}
}
ret[i][j] = (unsigned char) value;
continue;
}
//5X5 Window
for (row=-2; row<=2; row++)
{
for (col=-2; col<=2; col++)
{
if (edge[i+row][j+col] == 255)
{
flag = 2;
break;
}
}
if (flag == 2)
break;
}
if (flag == 2)
{
value = 0;
for (int row=-2; row<=2; row++)
{
for (int col=-2; col<=2; col++)
{
value += (img[i+row][j+col] * gKernal5[(row+2)*5 + col + 2]);
}
}
ret[i][j] = (unsigned char) value;
continue;
}
// Not in 5 x 5 Window
value = 0;
for (int row=-3; row<=3; row++)
{
for (int col=-3; col<=3; col++)
{
value += (img[i+row][j+col] * gKernal7[(row+3)*7 + col+3]);
}
}
ret[i][j] = (unsigned char) value;
}
}
return ret;
}
/* FUNCTION TO DISPLAY A MATRIX, DEBUG PURPOSE ONLY */
void showImage(unsigned char **img, int ncols, int nrows, char *name)
{
int value;
IplImage * disImg = cvLoadImage("e:\\test\\meanface.bmp",0);
for (int i=0; i<ncols; i++)
{
for (int j=0; j<nrows; j++)
{
value = (int) img[i][j];
iplPutPixel(disImg, j, i, &value);
}
}
cvNamedWindow( name, CV_WINDOW_AUTOSIZE );
cvShowImage( name, disImg );
}
/* FUNCTION TO WRITE AN IMAGE ARRAY INTO A BMP FILE */
void saveImage(unsigned char **img, int ncols, int nrows, char *name)
{
int value;
IplImage * disImg = cvLoadImage("e:\\test\\meanface.bmp",0);
for (int i=0; i<ncols; i++)
{
for (int j=0; j<nrows; j++)
{
value = (int) img[i][j];
iplPutPixel(disImg, j, i, &value);
}
}
cvSaveImage( name, disImg );
}
/* OPTIMAL THRESHOLD SEGMENTATION */
unsigned char **segmentation(unsigned char **x, int nrows, int ncols, int mode)
{
int i, j, thr, t, c=0, d;
double p[256], q1, q2, u1, u2, q1n, q2n, u1n, u2n, h, hmax, u, tmin, tmax;
unsigned char **y = (unsigned char **)matrix(nrows+2, ncols+2, -1, -1, sizeof(char));
/* INITIATE THE HISTROGRAM */
for(i=0; i<=255; i++)
p[i] = 0;
for(i=0; i<nrows; i++)
{
for(j=0; j<ncols; j++)
{
if (mode==0)
{
p[x[i][j]]++;
}
else
{
if (x[i][j] < 150)
{
p[x[i][j]]++;
c ++;
}
}
}
}
if (mode==0)
for(i=0; i<=255; i++)
p[i] /= (nrows*ncols);
else
for(i=0; i<=255; i++)
p[i] /= c;
/* INITIATE THE PARAMETERS */
for(i=0; p[i]==0; i++);
tmin = i + 1;
for(i=255; p[i]==0; i--);
tmax = i - 1;
u = 0;
for(i=0; i<=255; i++)
u += (i*p[i]);
q1 = q2 = 0;
u1 = u2 = 0;
for(i=0; i<=tmin; i++)
{
q1 += p[i];
u1 += (i*p[i]);
}
q2 = 1 - q1;
u1 /= q1;
u2 = (u - q1*u1) / q2;
/* COMPUTE THE THRESHOLD */
hmax = 0;
for(t=tmin; t<=tmax; t++)
{
q1n = q1 + p[t];
q2n = 1 - q1n;
u1n = ( (q1 * u1) + t * p[t] ) / q1n;
u2n = ( u - q1n * u1n ) / q2n;
q1 = q1n;
q2 = q2n;
u1 = u1n;
u2 = u2n;
h = q1 * q2 * (u1 - u2) * (u1 - u2);
if(h > hmax)
{
hmax = h;
thr = t;
}
}
for(i=0; i<nrows; i++)
{
for(j=0; j<ncols; j++)
{
if(x[i][j]>thr)
{
y[i][j] = 255;
}
else
{
d = (int) (sqrt(1600-((double)i-40)*((double)i-40)/1.7)+0.5);
if ( (i > 40) && (j > (40 + d) || j < (40 - d)) )
y[i][j] = 255;
else
y[i][j] = 0;
}
}
}
return y;
}
/* FUNCTION TO CALCULATE THE MEAN VALUE OF AN IMAGE */
int meanValue(unsigned char **x, int i, int j, int s)
{
int sum = 0;
for (int row = -s; row <=s; row ++)
for (int col = -s; col <= s; col ++)
sum += x[i+row][j+col];
s = s*2+1;
sum = (int) (((float)sum / (s*s))+0.5);
return sum;
}
/* FUNCTION TO CALCULATE THE NORM OF AN IMAGE */
float normImage(unsigned char **x, int nrows, int ncols)
{
float sum=0;
for(int i=0; i<nrows; i++)
for(int j=0; j<ncols; j++)
sum += (x[i][j]*x[i][j]);
sum = sum/(nrows*ncols);
return sum;
}
References:
[1] M. Turk, A. Pentland, Eigenfaces for recognition, J. Cogn. Neurosci. 3 (1991) 71-86.
[2] D.H. Liu, K.M. Lam, L.S. Shen, Illumination invariant face recognition, Patter Recognition, 38 (2005) 1705-1716.
[3] P.N. Belhumeur, J.P. Hespanha, D.J. Kriengman, Eigenfaces vs. fisherfaces: recognition using class specific linear projection, IEEE Trans. Pattern Anal. Mach. Intell, 19 (7) (1997) 711-720.
[4] A. Hyvarinen, E. Oja, Independent Component Analysis: Algorithms and applications, Neural Networks, 13 (4-5) (2000) 411-430.
[5] G. Guo, S.Z. Li, K.L. Chan, Support vector machines for face recognition, Image Comput. 19 (2001) 631-638.
[6] M.J. Er,
[7] Y. Adini, Y. Moses,
[8]
[9] N. Otsu, A threshold selection method from gray-level histograms, IEEE Trans. Systems, Man, and Cybernet, 9 (1) (1979) 62-66.
[10] Canny, John, A computational approach to edge detection, IEEE Trans. Pattern Anal. Mach. Intell, 8 (6) (1986) 679-698.
[11] Intel Corporation, Open source computer vision library reference manual, December 2001.
[12] Intel Corporation, Intel image processing library reference manual, August 2000.
[13] X.D. Xie, K.M. Lam, Face recognition under varying illumination based on a 2D face shape model, Pattern Recognition 38 (2005) 221-230.
[14] R. Gross, I. Matthews, S. Baker, Appearance-based face recognition and light-fields, IEEE Trans. on Pattern Analysis and Machine Intelligence, 26 (4) (2004) 449-465.
[15] R. Basri, D.W. Jacobs, Lambertian reflectance and linear subspaces, IEEE Trans. on Pattern Analysis and Machine Intelligence 25 (2) (2003) 218-233.